How dangerous is encoded reasoning
(Cross-posted at https://www.lesswrong.com/posts/RErJpFwDtwckH2WQi/how-dangerous-is-encoded-reasoning)
Encoded reasoning occurs when a language model (LM) agent hides its true reasoning inside its chain-of-thought (CoT). It is one of the three types of unfaithful reasoning[1] and the most dangerous one because it undermines CoT monitoring , enables scheming and collusion (undesired coordination).[2] Only a few publications[3] [4][5] [6] tried to elicit encoded reasoning and all showed only rudimentary or 1-bit information hiding. Still, the question remains: how dangerous and probable is this? This post attempts to map out the research in steganography and watermarking with the relation to encoded reasoning. What is steganography? What is watermarking? How do they relate to encoded reasoning? What are their essential parts? What are their causes? What are their important properties? How does encoded reasoning relate to steganography and watermarking? What are the implications for safety?
Steganography
Before the rise of the Web, steganography was not something researchers were interested to rigorously study, it seemed to be some hacks that exploited human cognition like invisible inks or imperceptible modifications. Claude E Shannon[7] wrote that “concealment systems (steganography) are primarily a psychological problem”. Nowadays, steganography is a separate research direction in infosecurity. And watermarking/steganography has hundreds of publications per year. ArXiv already has 333 publications in 2025, compared to 321 in all of 2024 and only 43 in 2015. Gustavus J. Simmons[8] was the first to describe “subliminal channel” or steganography system (stegosystem), which is the prisoners’ problem (not to be confused with the prisoners’ dilemma from game theory). Then, Christian Cachin[9] defined the security of this channel from an information-theoretic view. And since then, as software and the Internet were being massively adopted, we see the similar rise of interest in steganography / watermarking to protect copyrights or improve digital security. The most significant work that summarized different approaches for image steganography from these years is by Jessica Fridrich[10] .
Steganography (literally ‘covered writing’) is the concealment of information such that its presence remains undetected. It differs from watermarking which is when all samples of media or text are marked with a hidden signature to identify the origin of a media. Watermarking embeds information tied to the original content itself, i.e. a music file has the watermark of a producer, a text — a flag that it is LLM generated. Steganography doesn’t have to be linked to the cover, the hidden message can be something entirely different or it might not be present at all. Also importantly, steganography is a communication between Alice (sender or encoder) and Bob (receiver or decoder), while watermarking is only embedding a hidden information. Usually 1 bit that indicates whether something is watermarked or not. Then, fingerprinting is a watermarking when all samples are marked with unique signature such that each copy can be identified. Unlike cryptography, which focuses on encrypting the content, i.e. creating a ciphertext, steganography targets the secret transmission of information, but similarly to cryptography, steganography creates a form of media that covers a secret, i.e. stegotext if the media is text. This is the security through obscurity principle, which means that the goal is hidden communication, i.e. Eve (eavesdropper or monitor or guard or warden) won’t detect the presence of a hidden message. Hence, watermarking is not actually steganography as the presence of a hidden message is known to Eve. Another important difference from watermarking is steganography requires higher secret channel capacity which comes with the expense of robustness (more about that below).
The primary goal of steganography is to hide the presence of a hidden message. There are mainly two approaches to measure how good stegosystems are at this goal, namely how secure stegosystems are. The first is information-theoretic[11] where a stegosystem is $\epsilon$-secure if the Kullback-Leibler divergence $D_{KL}(P_c \parallel P_s) \leq \epsilon$. If $\epsilon=0$, then it is perfectly secure. And another one is complexity-theoretic[12] which grounds the security on the inability of Eve to construct an attack with polynomial upper bound, then the system is considered secure. Complexity-theoretic approach tries to be more grounded and realistic, while information-theoretic approach allows unbounded time for Eve to detect subliminal channels and gives Eve the full knowledge of a cover space distribution which were not realistic at the time of Hopper in 2004. Then, Eve possesses (or assumed to possess) all the knowledge and tools that Alice and Bob have except the private key, according to Kerckhoffs’s principle.
Information-theoretic approach doesn’t tell anything about security when Eve can interfere, in that case, a stegosystem should be robust to these modifications to stay secure, which is another research direction. Eve can try to modify or delete words, paraphrase, insert new messages, pretend to be Bob, and so on.[13]
Steganography or watermarking is in essence a two way function, encoding and decoding, with the requirement to resist the attacks of Eve. Steganalysis represents the other side, the attacks of Eve. More specifically, stegosystem is a subliminal channel, which consists of 1. communication channel; 2. embedding (Alice) and 3. extracting mechanisms (Bob); 4. cover source; 5. message source; and 6. the presence of surveillance (Eve) (otherwise the channel can be overt). For real security, there are another two requirements: 7. private key source, and 8. (pseudo) random number generator (RNG); otherwise Eve can run the same embedding or extraction function to detect the presence of the hidden message, and the private key and RNG allow to use (pseudo) random encoding/extraction path (tokens in the case of encoded reasoning).
Similarly to the capacity of a communication channel, steganography capacity is the maximum transmission rate or the mutual information[14] for a stegosystem. In practice, actual capacity is hard to measure because it relates to how distorted the cover will be, which depends on a steganalysis and the level of required security or robustness. Instead, studies typically compute decoded bits per some unit (KB, word, token, answer)[15] assuming some level of security (passive or active Eve, blind steganalysis or not, etc.). For example, see R. Bala Krishnan, Prasanth Kumar Thandra, and M. Sai Baba[16] , where only a few reached about 1 bit per token (they counted bits per cover-character, like 4.5 chars for a synonyms substitution steganography which is basically one word).
Following Kerckhoffs’s principle, Alice and Bob should share a private key (like in symmetric encryption) or Alice should use Bob’s public key (public key steganography). What if they did not exchange a key beforehand? Well, then it is the zero-shot coordination problem, i.e. the problem of coordination without prior communication. In the absence of a shared key, Alice and Bob can try to come up with an option that each of them thinks the other one will choose by default, i.e. the Schelling or focal point. Eve can try to attack this coordination and ask Alice and Bob to choose a Schelling point and impersonate either Alice or Bob.
Alice and Bob need PRNGs in order, among other things, to determine which tokens (or pixels in the case of image steganography) to modify (so the modification path is not just sequential), or to additionally encrypt the payload before embedding.
Steganalysis is the counterpart for steganography, i.e. it is an effort to detect steganography, tell stegotext or not with more than a random chance. If it tries to actually decode a hidden message then it is forensic steganalysis, which is practically harder than just detection, but easier if a steganography algorithm is known, i.e. non blind vs blind steganalysis.
However, all that was before the deep nets era, starting from around 2017 the landscape changes radically. Now we can easily sample a cover source, we know cover distribution which was the primary obstacle for steganography before.
Deep Steganography
The next phase was the rise of deep nets, which we currently live in. There are an abundance of publications on how to leverage deep nets or LLMs for steganography or watermarking. The earliest work seems to be Tina Fang, Martin Jaggi, and Katerina Argyraki[17] . An example of a recent significant work on watermarking is Sumanth Dathathri et al.[18] published in Nature. The interest in watermarking/steganography seems strongly correlated with the interest in LLMs. See the publications at arXiv mentions earlier, or this graph from Liu et al.[19] :
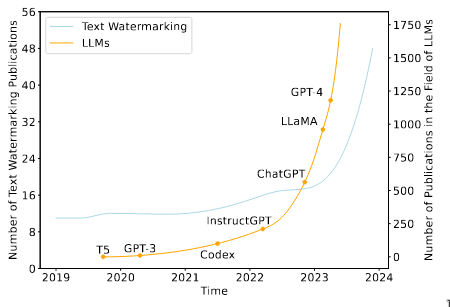
Deep neural networks with ever improving distribution of a cover space enabled Alice and Bob to actually implement perfectly secure steganography (information-theoretic security, see definition above). And indeed there are algorithms to do that[20] [21]. Basically, deep steganography is steganography that is done with the help of a deep net such as a large language model, i.e. by sampling tokens distribution. There are numerous studies of how to leverage the LLMs to do steganography.[22] In our discussion however it is more important, if LM agents can do it.
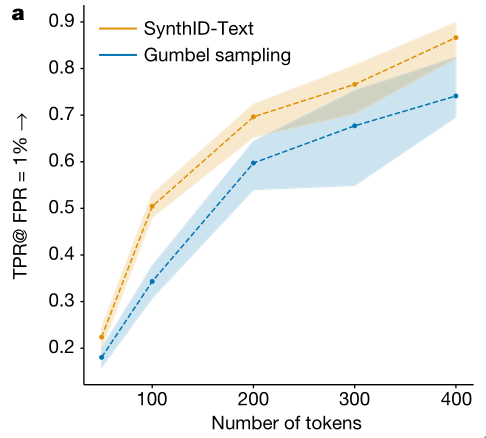
The reason why there is such popularity of steganography is because we can improve capacity and robustness. Before deep steganography, researchers only could suggest non-robust steganography algorithms based on tricky text or style modifications, which were vulnerable to active Eve; nowadays watermarking can withstand large modifications while preserving a hidden message. Current watermarking techniques[23] require about 100 tokens (watermark size) for good detection (<2% false positive rates) to encode 1 bit (watermarked or not) while withstanding distortions. However in practice, scalable watermarks require several hundreds of tokens more, 200-400[24] (the figure below). For robust transmission of several bits, algorithms require thousands of tokens, for example, Neil Perry et al.[25] encodes 3 bits per 8000 tokens. If high robustness is not a requirement, then there are algorithms that can encode about 1 bit per token[26] . In general, the more tokens an algorithm has to encode, the more robust it can be and vice versa.[27]
While deep steganography shows how neural networks enable sophisticated information hiding, the real concern for AI safety is when the language models themselves become the steganographers. What happens when LM agents actively use these techniques to conceal their reasoning?
LM Agent Steganography
LM agent steganography refers to when an agent uses steganography to hide secrets in tokens in order to accomplish something. This is not just a function that encodes and decodes secrets, but an agent that actively avoids detection. Steganography can be used to cover an agent’s actual reasoning (encoded reasoning), then Alice and Bob are the same character, or it can be used for the communication between two or more agents to secretly coordinate, which is called secret collusion. In both cases, we have a similar process, only the addressee changes. The steganography process, though, needs a steganography procedure and computation.
An example of encoded reasoning in real life would be a LM agent for R&D / ML research that does two tasks. It plans a bug fix and at the same time it reasons on how to insert a backdoor. The ML agent has two objectives: the good objective, which is expressed in CoT, and its another hidden objective. We want to elicit that hidden object. As such, encoded reasoning is an instance of deceitful alignment[28] and an ELK problem[29] for LM agents. ELK aims to determine if a model is attempting to deceive us and this is similar to the situation where encoded reasoning conceals a different reality.
LM agent steganography or encoded reasoning is like a programming code or an algorithm that describes how to embed and extract a secret. Alice or Bob, now both LM agents, can store the procedure “inside them”, or the procedure can take place as input tokens sourced from the model itself, from a tool call, or some other way. After that, they need to compute encoded tokens, i.e. a stegotext, or decode tokens to get a secret. I think we can distinguish between fully encoded reasoning and external or partial encoded reasoning.
Fully encoded reasoning might happen as illustrated in the figure below. It runs for each forward pass: both a steganography procedure and a computation happens inside each forward pass each time a new token is outputted. A new encoded token $x[i+1]$ is the output of the encoding or embedding function, $f$, that takes previous encoded tokens, $x[:i]$ and the distribution for i-th token, $P_{LM}(\cdot|x[:i])$ to do deep steganography. The function $f$ also takes secret tokens, $y[:i+1]$ to encode them. The decoding or extraction happens also each time the model produces next token: to decode a token, $y[i]$, the decoding function, $f’$, requires previous encoded tokens up to i-th token, $x[:i]$, and the distribution for it, $P_{LM}(\cdot|x[:i])$, in case of deep steganography.
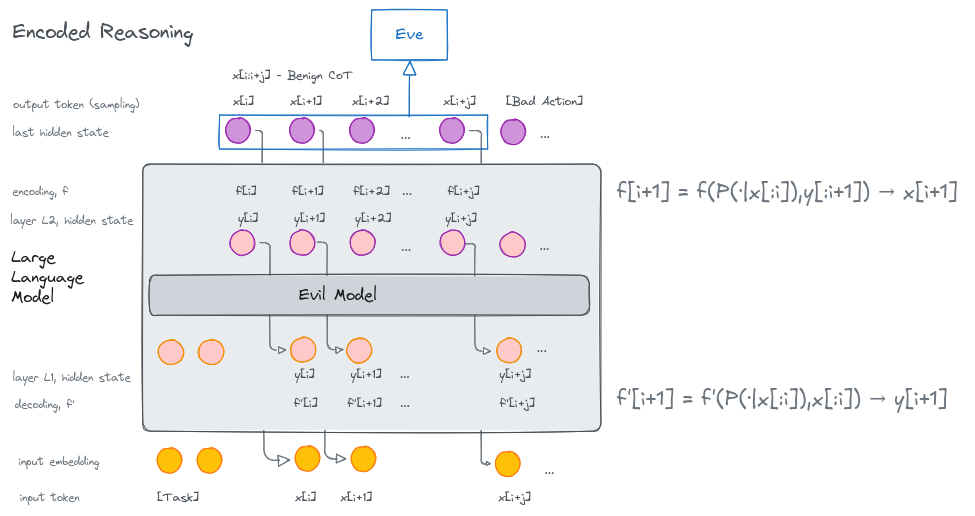
Encoded reasoning seems to be the most dangerous type of LM agent steganography. The danger comes from the fact that Eve can only see the covered tokens, $x[i:i+j]$, which puts Eve in the position of blind steganalysis. To overcome that Eve might use some white box monitoring to check if hidden states relate to the encoding or decoding, but that entails extra cost and complexity.
In external encoded reasoning (see figure below), Alice devises a bad plan using tokens $x[i:i+j]$ (malign CoT), and encodes the plan into good looking tokens (benign CoT), $x[i+j+1:i+j+k]$, so Bob afterwards can decode those tokens, $x[i:i+j]$, and try to do the bad action. The difference from the full encoded reasoning is that Eve can easily detect this if Eve checks all CoT, otherwise Eve is in the same position as Eve observing full or internal encoded reasoning.
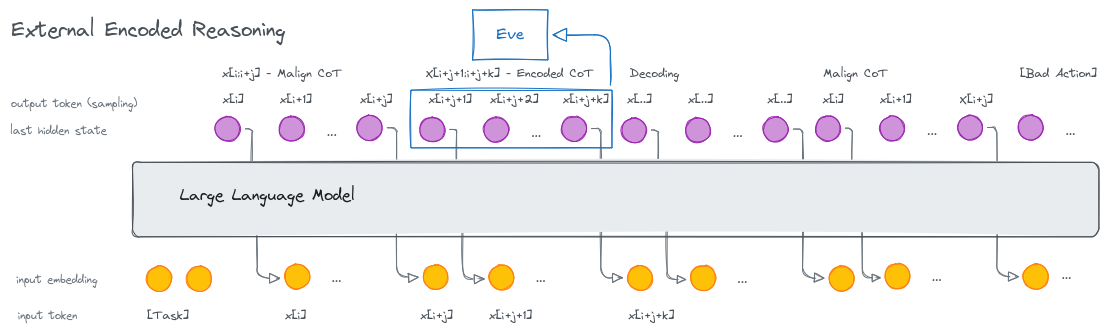
There can be some mix of these two types, for example encoding might require externalized reasoning in CoT, while decoding might happen during forward pass. In that case, the decoding might not require the sampling of an LM, like it was done in Dathathri et al.[30] . However, it is essential for deep steganography to have the cover source sampling ability as we discussed above, otherwise Alice and Bob are back to the methods of steganography before the deep nets era, which are limited and are easier to detect.
Without a private key the security of a secret channel is low, because Eve can run the same steganography algorithm. For example, if Eve knows that Alice uses the arithmetic coding algorithm,[31] Eve can measure KL divergence between the stegotext and the cover, assuming Eve knows which tokens were used, because the arithmetic coding algorithm is not that secure. Hence, again, the requirement for a shared private key (or a public key) to choose (pseudo) random tokens or even encrypt the secret. However, that faces another problem, the zero-shot coordination, i.e. coordination on which keys to use without prior communication (Schelling points), because exchanging keys beforehand seems hard.
Implications and Open Questions
How likely is encoded reasoning? How dangerous is it? That basically boils down to what Eve can see and the ability of Alice/Bob to use extra tools like LM sampling and shared keys. The most worrisome situation is the full encoded reasoning, but that seems unlikely to happen without specific fine tuning, because to decode token $y[i]$, Bob requires LM distribution for tokens up to $i$, $p_{LM}(\cdot|x[:i])$ , and Bob requires it at the layer before the layers where the malign CoT happens ($L1$ at the picture), which is positioned way down below, which means the token distribution for this CoT is unlikely to be available to Bob there, as the last layer hidden state is mapped to the tokens and are lost each time the model autoregressively generates tokens. Or the benign CoT should happen before the malign CoT to provide the LM distribution for the decoding function, $f’$. Of course Bob can use simpler steganography methods like shifting words or making grammar errors, but that should increase the KL divergence and be detectable by Eve. And in the case of external encoded reasoning, where Alice exposes the encoding in external tokens, Eve can just read those tokens to raise an alarm, or Alice and Bob might just lack the affordances to do deep or private/public key steganography. So it seems that encoded steganography is unlikely or easily detectable. And external encoded steganography is not what someone trains their LM agents. Therefore, with good monitoring measures, LM agent steganography seems not that dangerous so far.
So far we have only two limited demonstrations of encoded reasoning. Roger and Greenblatt[32] do a supervised fine tuning of GPT 3.5-Turbo to do the mapping of 18 phrases to one bit value (liberal or not), which has high KL divergence, meaning the text is too suspicious even for an unequipped Eve. Mathew et al.[33] demonstrates 1 bit encoding where Bob is a classifier model (fine tuned BERT based model). Other attempts had negative results[34] [35] [36].
Do Alice and Bob have private space which is not monitored by Eve? If so they might use that to hide their reasoning. That might happen in the case of massive adoption of LM agents and not using monitors because of their cost. Partial observation of CoT or only actions monitors are not enough for high security as shown above.
Conclusion
This post explored how steganography has evolved from exploiting human perceptual limitations to leveraging neural networks for near-perfect information-theoretic security, and how this relates to encoded reasoning in LMs. Despite theoretical possibilities, current demonstrations show only limited information hiding, with full encoded reasoning facing significant technical barriers due to LM architecture constraints. While encoded reasoning poses risks by potentially undermining CoT monitoring and enabling secret collusion between agents—representing a concrete instance of deceptive alignment and connecting to the ELK problem—these threats appear manageable with proper monitoring. External encoded reasoning is detectable through CoT inspection, and internal encoded reasoning requires specific fine-tuning and coordination mechanisms (like shared keys) that face the zero-shot coordination problem. The current limited capabilities of LM agent steganography suggest we have time to develop robust detection methods, but as models gain access to better tools and sampling abilities, continued research into both offensive capabilities and defensive measures remains essential.
Tamera Lanham et al., “Measuring Faithfulness in Chain-of-Thought Reasoning,” July 16, 2023, http://arxiv.org/abs/2307.13702. ↩︎
Lewis Hammond et al., “Multi-Agent Risks from Advanced AI,” February 2025. ↩︎
Fabien Roger and Ryan Greenblatt, “Preventing Language Models From Hiding Their Reasoning,” October 31, 2023, https://doi.org/10.48550/arXiv.2310.18512. ↩︎
Sumeet Ramesh Motwani et al., “Secret Collusion Among Generative AI Agents,” August 28, 2024, https://doi.org/10.48550/arXiv.2402.07510. ↩︎
Yohan Mathew et al., “Hidden in Plain Text: Emergence & Mitigation of Steganographic Collusion in LLMs,” October 2, 2024, https://doi.org/10.48550/arXiv.2410.03768. ↩︎
Artem Karpov et al., “The Steganographic Potentials of Language Models,” 2024, https://openreview.net/forum?id=Gysw3qsASx#discussion. ↩︎
“Communication Theory of Secrecy Systems,” The Bell System Technical Journal 28, no. 4 (1949): 656–715. ↩︎
“The Prisoners’ Problem and the Subliminal Channel,” in Advances in Cryptology: Proceedings of Crypto 83, ed. David Chaum (Boston, MA: Springer US, 1984), 51–67, https://doi.org/10.1007/978-1-4684-4730-9_5. ↩︎
“An Information-Theoretic Model for Steganography,” in Information Hiding, ed. David Aucsmith, vol. 1525 (Berlin, Heidelberg: Springer Berlin Heidelberg, 1998), 306–18, http://link.springer.com/10.1007/3-540-49380-8_21. ↩︎
Steganography in digital media: principles, algorithms, and applications, 1. publ (Cambridge: Cambridge Univ. Press, 2010). ↩︎
Cachin, “An Information-Theoretic Model for Steganography.” ↩︎
M. Blum and Nicholas Hopper, “Toward a Theory of Steganography,” 2004, https://www.semanticscholar.org/paper/Toward-a-theory-of-steganography-Blum-Hopper/4c9e54cdcd31e8101424d6a2765843a49953ae1f. ↩︎
See taxonomy in 5.5, Aiwei Liu et al., “A Survey of Text Watermarking in the Era of Large Language Models,” August 2, 2024, https://doi.org/10.48550/arXiv.2312.07913. ↩︎
P.19, T. M. Cover and Joy A. Thomas, Elements of Information Theory, 2nd ed (Hoboken, N.J: Wiley-Interscience, 2006). ↩︎
Liu et al., “A Survey of Text Watermarking in the Era of Large Language Models.” ↩︎
“An Overview of Text Steganography,” in 2017 Fourth International Conference on Signal Processing, Communication and Networking (ICSCN), 2017, 1–6, https://doi.org/10.1109/ICSCN.2017.8085643. ↩︎
“Generating Steganographic Text with LSTMs,” May 30, 2017, https://doi.org/10.48550/arXiv.1705.10742. ↩︎
“Scalable Watermarking for Identifying Large Language Model Outputs,” Nature 634, no. 8035 (October 2024): 818–23, https://doi.org/10.1038/s41586-024-08025-4. ↩︎
“A Survey of Text Watermarking in the Era of Large Language Models.” ↩︎
Zachary Ziegler, Yuntian Deng, and Alexander Rush, “Neural Linguistic Steganography,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), ed. Kentaro Inui et al. (EMNLP-IJCNLP 2019, Hong Kong, China: Association for Computational Linguistics, 2019), 1210–15, https://doi.org/10.18653/v1/D19-1115. ↩︎
Christian Schroeder de Witt et al., “Perfectly Secure Steganography Using Minimum Entropy Coupling,” October 30, 2023, https://doi.org/10.48550/arXiv.2210.14889. ↩︎
Liu et al., “A Survey of Text Watermarking in the Era of Large Language Models.” ↩︎
Julien Piet et al., “Mark My Words: Analyzing and Evaluating Language Model Watermarks,” October 11, 2024, https://doi.org/10.48550/arXiv.2312.00273. ↩︎
Dathathri et al., “Scalable Watermarking for Identifying Large Language Model Outputs.” ↩︎
“Robust Steganography from Large Language Models,” April 11, 2025, https://doi.org/10.48550/arXiv.2504.08977. ↩︎
Ziegler, Deng, and Rush, “Neural Linguistic Steganography.” ↩︎
Liu et al., “A Survey of Text Watermarking in the Era of Large Language Models.” ↩︎
Evan Hubinger et al., “Risks from Learned Optimization in Advanced Machine Learning Systems,” arXiv.org, June 5, 2019, https://arxiv.org/abs/1906.01820v3. ↩︎
Eliciting Latent Knowledge, Paul Christiano, Ajeya Cotra, and Mark Xu, “Eliciting Latent Knowledge (ELK),” Google Docs, December 2021, https://docs.google.com/document/d/1WwsnJQstPq91_Yh-Ch2XRL8H_EpsnjrC1dwZXR37PC8/edit?usp=sharing&usp=embed_facebook. ↩︎
“Scalable Watermarking for Identifying Large Language Model Outputs.” ↩︎
Ziegler, Deng, and Rush, “Neural Linguistic Steganography.” ↩︎
“Preventing Language Models From Hiding Their Reasoning.” ↩︎
“Hidden in Plain Text.” ↩︎
Fabien Roger, “Some Negative Steganography Results,” December 9, 2023, https://www.lesswrong.com/posts/EEvsL9cpgDAxAhTzt/some-negative-steganography-results. ↩︎
Karpov et al., “The Steganographic Potentials of Language Models.” ↩︎
Robert Mccarthy et al., “Can LLMs Learn Steganographic Reasoning via RL?” April 11, 2025, https://www.lesswrong.com/posts/KRKnFdECZMu3Ej3z6/can-llms-learn-steganographic-reasoning-via-rl. ↩︎